想让机器人像人一样思考,似乎一直是个难题。例如,让智(zhi)能(zhang)机器人去客厅拿个遥控器,结果看到机器人在厨房翻箱倒柜…
好消息是,这个问题现在被CMU解决了。CMU研究团队打造出了一款拥有人类「常识」的导航机器人,让找东西变得更方便。这款机器人能利用AI判断家中最可能找到目标物体的地点,从而尽快找到它。

项目已被ECCV 2020收录,并获得了居住地目标导航挑战赛的第一名。
一起来看看实现的过程。
事实上,以往大部分采用机器学习训练的语义导航机器人,找东西的效果都不太好。相比于人类潜意识中形成的常识,机器人往往有点“死脑筋”,它们更倾向于去记住目标物体的位置。但物体所处的场景往往非常复杂,而且彼此间差异很大(正所谓每个人的家,乱得各有章法),如果单纯以大量不同场景对系统进行训练,模型泛化能力都不太好。于是,相比于用更多的样本对系统进行训练,这次研究者们换了一种思路:采用半监督学习的方式,使用一种名为semantic curiosity(语义好奇心)的奖励机制对系统进行训练。

训练的核心目的,是让系统基于对语义的「理解」来确定目标物体的最优位置,换而言之,就是让机器人“学点常识”。
一旦确定了物体最可能出现的地方,机器人就能通过导航,直接去往预计的位置,并快速检测到目标物体的存在,这个过程被称之为探索策略(exploration policy)。
采用Mask RCNN训练探索策略
如下图所示,策略的实现被分成了三步:学习、训练、测试。
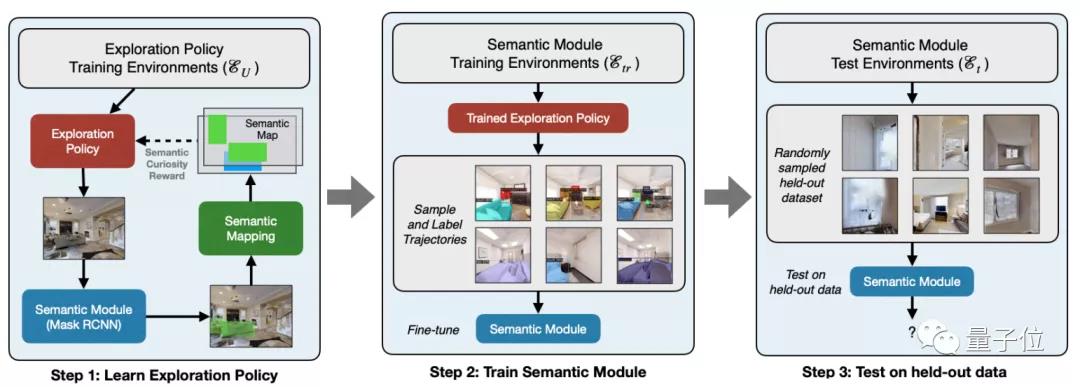
首先,采用Mask RCNN对图像从上至下进行目标预测,用于训练探索策略,后者负责生成目标检测和场景分割所需的训练数据。对训练数据进行标记后,数据会被用于微调和评估目标检测及场景分割的效果。在目标检测的过程中,即使面对某一物体的镜头转360度,机器人也必须将之识别为同一种物体。这其中最关键的一个步骤,在于构造语义地图。
构造「有魔法的」地图
从下图可见,图像被处理成RGB和Depth两种模式。
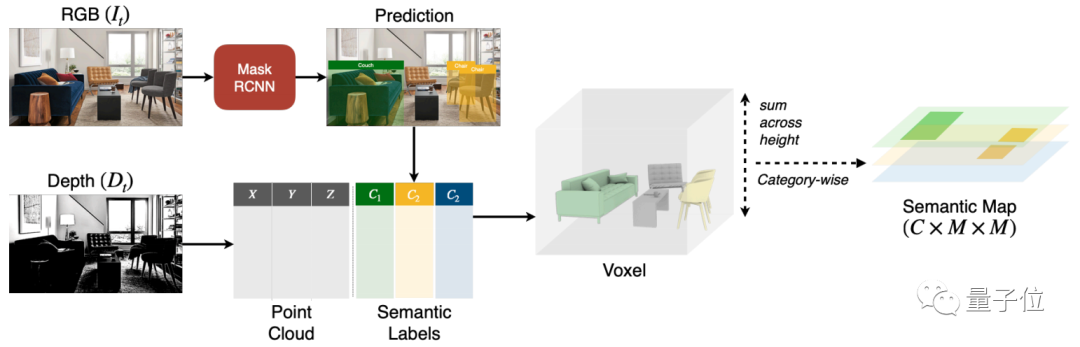
其中,RGB图像会通过Mask RCNN网络,用于获得目标分割预测。而Depth架构,则被用于计算点云,其中的每个点,都会在Mask RCNN的预测结果基础上与语义标签进行关联。最后,基于几何计算,会在空间中会生成一个三维立体图。每一个通道用于表示一种物体类别,原本2D的地图就会转变成一个3D的语义地图。有了语义地图,机器人在移动时也能准确地对3D空间进行目标预测了。
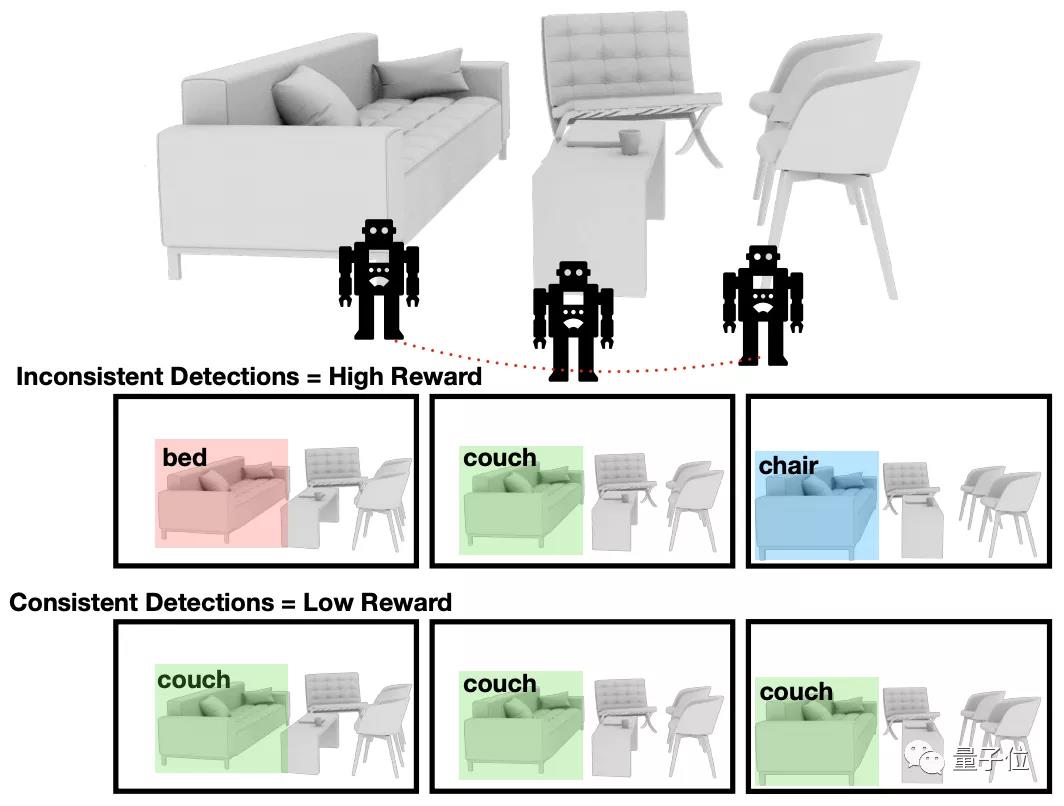
不过,这会出现一种情况,如果目标物体在不同的帧上被预测的标签不同,那么语义图中对应这个物体的多个通道都会是1。如下图,不同的时间,系统预测的目标标签可能并不一样,有时候是床,有时候则变成了沙发。

论文定义了语义好奇心累计奖励(cumulative semantic curiosity reward),指占语义地图中所有元素总和的比例。
而语义好奇心奖励机制,则采用强化学习的方式,目的是使这个比例最大化。
事实证明,这种方法非常有效。
机器人在训练过程中,可以专注地去理解目标物体与房间布局的关系,而非不停地进行路径规划。
训练出的机器人,在人机交互方向上变得更加容易操控。
例如,在各种方法下,即使探索区域不及倒数第二和第三种方法,但语义好奇心仍然检测出了相当的目标数量。
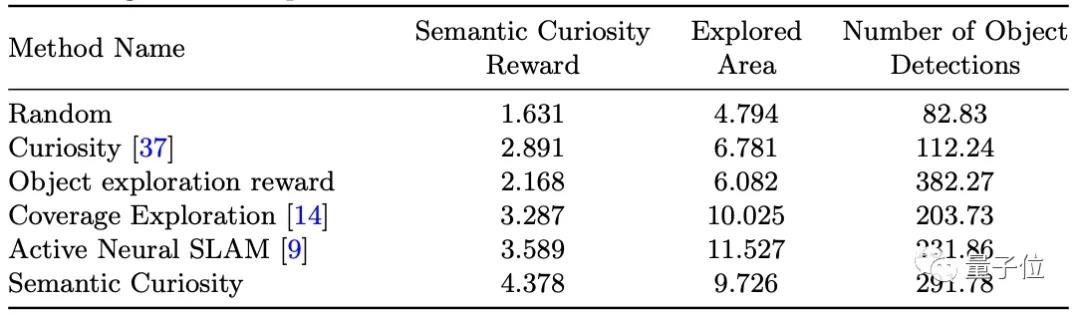
这说明它在进行目标检测时,能更专注于所需要探测的物体。
而从下图可见,语义好奇心明显发现了更多其他策略无法发现的物体,这对于检测目标是非常有效的。
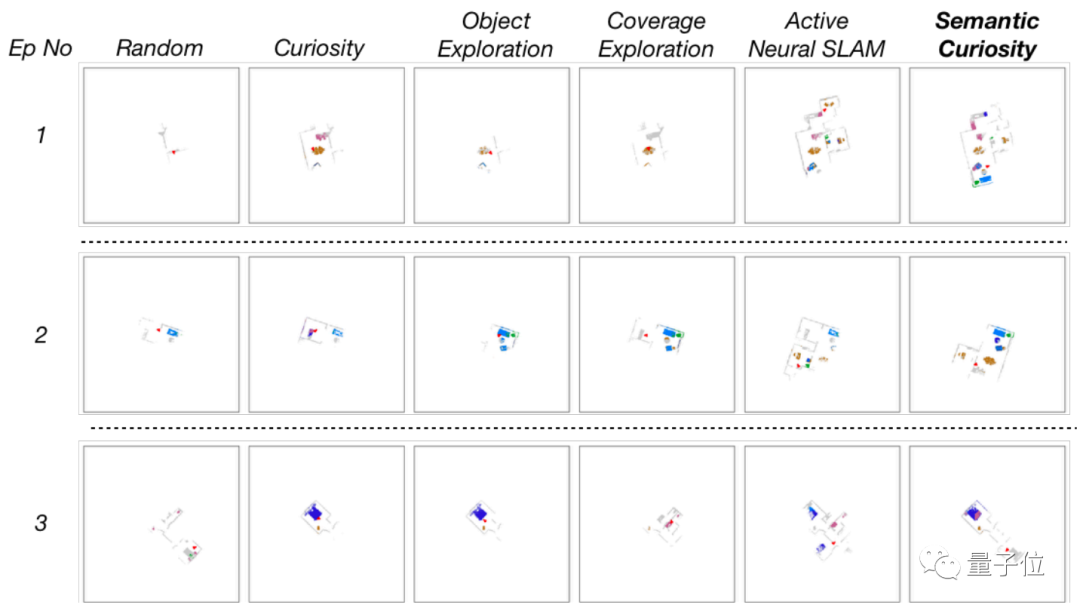
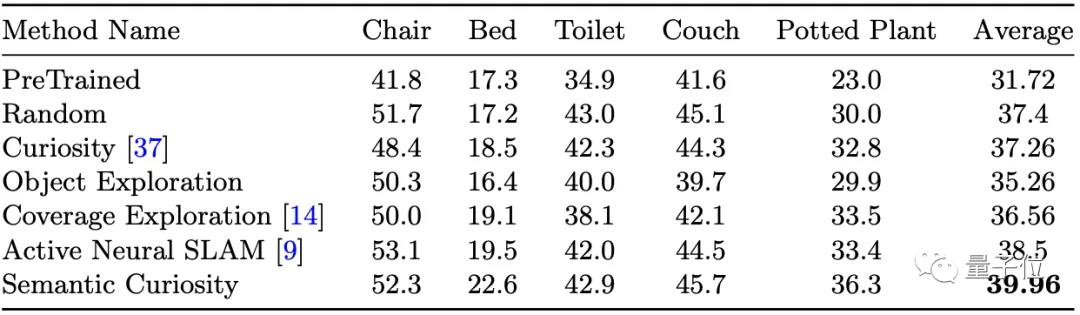
在最终的训练结果中,语义好奇心拿到了最高的39.96分。
— 完 —
转自量子位
侵权联系管理员删除
